
Dockerを使用するにあたって、
必ず直面するものとして、ホスト(自分のローカルPC)と
コンテナのデータの共有及びそれらの永続化があると思います。
本記事では、それを実現する、Dockerの重要概念である、
ボリュームとdocker cpなどの使用方法を主題にとりあげ、
ボリュームの共有方法のマウントの種類や、docker cpとの違いにも言及しつつ、
具体例としてMySQLコンテナを使ってみます。
本記事で得られるものとしては、
ポイント
- ボリュームマウントとバインドマウントの違い
- docker cpの使い方とマウントと比べたデメリット
- mysqlでのボリューム設定
- ボリュームマウントのバックアップ方法と復元方法
- docker desktop for macの特殊性
などがあります。
ボリュームは、Dockerを使う上で重要ですので、
ぜひとも最後まで御覧くださいますと幸いです。
docker cpコマンド
まず、ボリュームの前に、
docker cpコマンドについて触れていきます。
docker cp コマンドは、
Dockerコンテナとホスト間でファイルやディレクトリをコピーする際に使用されます。
ホストは、自分のPCと思ってもらえれば大丈夫です。
例えば、Vimや他のエディタがインストールされていないコンテナ内でファイルを編集したい場合、
その環境にVimとかをインストールするやり方と、
このdocker cpを使用してローカルマシンで編集したファイルを、
コンテナにコピーするやり方があります。
docker cp index.txt mycontainer:/tmp/htmlこのコードはindex.txtをローカルマシンから
mycontainerの指定されたディレクトリ(ここでは/tmp/html)にコピーします。
Linuxにもcpコマンドがありますが、
これがホストマシンからコンテナの中に変わっただけで、
基本は似たような感じかと思います。
これは、このあと紹介するvolumeを設定するまででもないような、
軽微な変更とかをサクッと適用したいときとかに便利です。
pushdコマンド
やや脱線ですが、
pushdコマンドというものがあり、これを使うと、
ディレクトリのスタックに現在のディレクトリを保存し、
新しいディレクトリに移動する際に使用されます。
これはcdコマンドとは異なり、popdを使って前のディレクトリに戻ることができます。
pushd /path/to/newdirectory
# 何らかの作業
popdこのコマンドは新しいディレクトリに移動し、その後元のディレクトリに戻ります。
ぶっちゃけ、zoxideみたいなチートコマンドもあるので、
これをピンポイントで使う機会はあまりないかもしれませんが、
docker cpとかをする際のディレクトリのパス指定に、
カレントディレクトリを変えたほうが便利な場合もあるかもしれませんので、
軽くこういうコマンドもあるんだなぐらいで押さえておくのがおすすめです。
ちなみに、zoxideみたいな便利コマンドについては、
下記の記事でご紹介しております。
-

-
参考Linux便利コマンド8選 zoxide/bat/exa/fzfなど
いつもcdとかcatのように、お決まりのコマンドを使うと思いますが、最近だと、こういったコマンドの強化版みたいなやつも熱いので紹介します。 本記事の内容は、下記動画でもご紹介したので、実際のハンズオン ...
続きを見る
docker cpで作成したデータが失われる場合
さて、こんな感じでdocker cpをしたデータですが、
永続化されるわけではありません。
Dockerでは、コンテナ内のデータは
コンテナのライフサイクルに依存します。
コンテナのライフサイクルについては、
下記の記事で少し言及しています。
-

-
参考【Dockerコマンド】よく使うものpull image run execなど
Dockerを使うには、Linuxと同様にいくつかの典型的なコマンドを使いこなす必要があります。 ただ、種類が多いことから「どれがどれだったっけ?」ってなることもしばしば。 本記事では、とりあえずこれ ...
続きを見る
さて、docker cpで作成したデータですが、
ポイント
- コンテナを停止して再開した場合、データは保持されます。
- コンテナをrestartした場合も、基本的にはデータは保持されます。
- しかし、コンテナを破棄して再起動した場合、新しいコンテナIDが生成されるため、
以前のコンテナで作成されたデータは失われます。
そのため、docker cpをするだけでは、
ファイルの内容を永続化するという観点では不十分です。
そのため、このようにファイルの内容とかを永続化する際は、
Dockerのボリュームという概念を用います。
ボリュームには、大きく分けてボリュームマウントとバインドマウントを利用します。(これは後ほど詳しく解説します)
これにより、コンテナが削除されてもデータはホストシステム上に残すことができます。
コマンドの形式としては、
docker run -v /path/on/host:/path/in/container myimageのような感じで、こちらはバインドマウントの場合です。
このコードは、ホストの/path/on/hostをコンテナの/path/in/containerにマウントし、
コンテナのデータをホストの指定したディレクトリに永続化します。
以下、ボリュームについて詳しく見ていきます。
ボリュームとは
ボリュームは、コンテナ間でデータを共有し、永続化するためのメカニズムです。
これにより、コンテナが削除された後もデータを保持できます。
先程の、docker cpでもホストとコンテナでデータを同期できる点で、
似てはいますが、下記の点で異なります。
ポイント
- リアルタイム動機(ボリュームは開発環境などでの編集がコンテナにも反映される。docker cpは実行時のみ)
- ボリュームマウントを使えば、複数の異なるコンテナ間でのボリュームの共有ができる
そのため、ユースケースとしては、
docker cpがログファイルなどの取り出しなどに使うのに対し、
開発環境などでの編集はバインドマウントなど用いられることが多いかと思います。
マウントっていうのは、ストレージデバイスやファイルシステムをアクセス可能な形でシステムに取り付けることで、
Dockerでは、ボリュームをコンテナの特定のパスにマウントすることで、データをコンテナにアクセス可能にします。
これにより、コンテナが破棄されてもデータを保持することができます。
マウントの種類としてボリュームマウントとバインドマウントが有名です。
バインドマウントとボリュームマウントの違い
バインドマウントは、ホストマシン上の任意のファイルやディレクトリをコンテナにマウントします。
これは開発環境でのファイルの共有に便利です。先述しましたが、
ホストとコンテナとの共有という意味では、docker cpと共通点がありますね。
これに対して、ボリュームマウントは、Dockerが管理する特定の場所にデータを格納します。
これは、本番環境でのデータの永続化に適していて、docker volume createコマンドなどで、
ボリュームを作成します。
実際にdocker composeなど、実務で使う頻度が多いマウントは、
どちらかというとボリュームマウントのような気がします。
ボリュームマウントの利点
ボリュームマウントは、特にデータベースのデータなど、
継続的に更新されるデータの保持に有効です。
これにより、コンテナが削除されてもデータは失われません。
dockerには、こうしたvolumeを操作するコマンドがあります。
docker volumeコマンド
docker volume コマンドは、
ボリュームの作成、管理、削除を行うために使用されます。
先程ちらっと出てきたvolumeの作成には、createを使います。
docker volume create myvolumeこのコマンドはmyvolumeという新しいボリュームを作成します。
docker volume ls
docker volume ls コマンドを使用すると、現在存在するすべてのボリュームの一覧が表示されます。
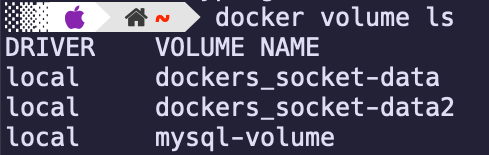
ここにDRIVERっていう項目があるかと思います。
これは、データのストレージ方式を管理するためのプラグインです。
これにより、異なるタイプのストレージシステムに対応し、データを効率的に管理できるようになります。
デフォルトは、localで、
これは、ローカルファイルシステムにデータを保存します。
他の種類として、overlayやaufsなどもありますが、
やや高度になるのと、あまりvolumeのdriverを設定することは、
そこまでない気がするので割愛します。
ちなみに、ややこしいのですが、
dockerのストレージドライバーとは微妙に違う概念で、
あくまでvolumeの保存作成などの形式かと思います。
ストレージドライバーについては、
下記の記事が詳しかったです。
https://docs.docker.jp/storage/storagedriver/index.html
--mountオプション
docker runとかで、
コンテナを起動する際、
volumeについてのオプションは、
-vで設定することが多いかもしれませんが、
これ以外に--mountオプションというものもあります。
--mountオプションは、ボリュームマウントの詳細な設定を行う際に使用されます。
-vオプションと比較すると、--mountはより詳細な設定が可能です。
--mount type=TYPE,source=SOURCE,destination=DESTINATIONtypeは、マウントのタイプを指定します。
通常はvolume(ボリュームマウント)、bind(ホストシステム上のファイルまたはディレクトリをコンテナにマウント)、
tmpfs(一時的なファイルストレージ)のいずれかを指定します。
sourceは、マウントするソース(ボリューム名、ファイルまたはディレクトリのパス)を指定します。
typeがvolumeの場合、これはボリュームの名前です。
typeがbindの場合、これはホスト上のファイルまたはディレクトリの絶対パスです。
destinationは、コンテナ内のマウントポイント(パス)を指定します。
例えば、myvolumeという名前のボリュームをコンテナの/appディレクトリにマウントする場合、
以下のようにdocker runコマンドに--mountオプションを追加します
docker run --mount type=volume,source=myvolume,destination=/app myimage--mountのほうが、詳細にvolume設定したい際は、
適しているかもしれません。
また-vでやった場合、
ボリュームマウントなのか、バインドマウントなのかわかりにくいという側面があるので、
可読性の観点でも、もしかすると--mountオプションの方がいいかもしれません。
ちなみに、-vオプションは、
マウント元が / から始まる絶対パスのときは、
バインドマウント、そうでないときはボリュームマウントとなります。
tmpfsマウント
今まで、ボリュームマウントとバインドマウントを中心に解説しましたが、
tmpfsマウントというものもあります。
tmpfsマウントは、一時的なファイルストレージとして利用され、
コンテナの再起動時にはデータが失われます。これは、一時ファイルやキャッシュに適しています。
基本的にはコンテナのライフサイクルに依存するので、
他のボリュームマウントとかみたいに、
データの永続化という点では向いていません。
セッションデータなどの一時的なデータの保存が適している点で、
NoSQLとかに少し役割が似ているかもしれません。
実際に、tmpfsマウントは、メモリ上でデータを処理するため、
ディスクベースのストレージよりも高速です。
docker run -d --name tmpfs-container --tmpfs /tmpfs-dir:rw,size=100m myimageこのコマンドは、myimageを基にtmpfs-containerというコンテナを起動し、
その中に/tmpfs-dirというディレクトリをtmpfsマウントとして作成します。
ここで指定されたsize=100mは、tmpfsマウントに割り当てるメモリのサイズを指定しています。
rwは読み書き可能っていうことですね。
中身は、コンテナの中に入って確認できる。
試しに何かフィアルを/tmpfs-dir配下で作ったあと、
restartをすると、
消えていることがわかると思います。
正直、頻繁には使うものではない気もしますが、
マウントの種類としては覚えておくといいかもしれません。
docker volume inspect
docker volume inspect コマンドは、特定のボリュームの詳細情報を提供します。
このコマンドは、ボリュームの設定や状態を確認するのに非常に便利です。
▒▓ ~ docker volume inspect mysql-volume
[
{
"CreatedAt": "2023-11-17T07:09:35+09:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/mysql-volume/_data",
"Name": "mysql-volume",
"Options": null,
"Scope": "local"
}
]このコマンドはmysql-volume(後のハンズオンで作成するやつ)の詳細情報を表示します。
特に注目したいのが、Mountpointです。
ボリュームのデータが物理的に保存されているホストシステム上(自分のPC)のパスを示します。
この例では /var/lib/docker/volumes/mysql-volume/_data にデータが保存されています。
(後に少し触れますが、docker desttop for macとかだと、
ホストPCでこのパスを確認しても実体が存在しないかと思います。)
MySqlコンテナを用いたボリュームマウント実装
ボリュームやマウントについて
大まかには紹介できたと思うので、
試しにmysqlコンテナを使って実装してみます。
MySQLコンテナでデータベースのデータを永続化する手順は、
下記のような感じになるかと思います。
- マウントディレクトリの指定: /var/lib/mysql
- 環境変数の設定: 例えばMYSQL_ROOT_PASSWORDを設定します。
- ボリュームの作成: docker volume createコマンドを使用してボリュームを作成します。
これを踏まえて、コンテナを立ち上げてみます。
例によっていきなりrunで立ち上げるので、
pullとかは不要です。
docker run -d \
-e MYSQL_ROOT_PASSWORD=mypassword \
-v mysql-volume:/var/lib/mysql \
mysql早速、コンテナの中に入って見ましょう。
docker exec -it コンテナID /bin/bashコンテナの中で、mysql -pコマンドを実行します。
mysql -pそうすると、パスワードを聞かれるので、
最初のrunで指定したパスワード入れます。
mysqlに入れたら、DATABASEを作りましょう。
CREATE DATABASE volumetest;作成したら、テーブルの挿入からデータの作成まで次のような感じで行います。
use volumetest;
create table blog (id INT NOT NULL AUTO_INCREMENT, title VARCHAR(50), PRIMARY KEY(id));
insert into blog (title) values ('test');さて、データを挿入できたら、
中身を確認してみます。
mysql> select * from blog;
+----+-------+
| id | title |
+----+-------+
| 1 | test |
+----+-------+
1 row in set (0.00 sec)selectしてみると、こんな感じで
データを入れることができていることがわかります。
用は済んだので、
ctrl + Dとかで抜けましょう。
試しにstopとrmをして、
このmysqlコンテナを消してみましょう。
docker stop コンテナID
docker rm コンテナIDそして、もう一度立ち上げてみます。
docker run -d \
-e MYSQL_ROOT_PASSWORD=mypassword \
-v mysql-volume:/var/lib/mysql \
mysql先程と同じ作業をして、
このコンテナのmysqlでselect文を実行してみると、
mysql> select * from blog;
+----+-------+
| id | title |
+----+-------+
| 1 | test |
+----+-------+
1 row in set (0.00 sec)さっきと同じデータがあることがわかりますね。
ちなみに、コンテナIDが変わっていたかと思うので、
先程とは別のコンテナになります。
volumeを使うことで、
このようにデータの共有ができるということですね。
ちなみに、最初に指定した、
volumeのマウントポイントですが、
docker desktop for macとかを使っていると、
これらが仮想化を使っている関係でファイルパスをホストPCから
直接見ることができません。
これを見る方法としては、
nsenterというものを使うのですが、
docker入門の枠からは外れるので割愛します。
ちなみに、nsenterで確認すると、
/var/lib/docker/volumes/mysql-volume/_data/volumetest/blob.ibdというファイルが作成されていることが
確認できました。
ボリュームマウントのバックアップ方法
次にこうしたボリュームのバックアップについて解説します。
Dockerでは、バックアップのために別のコンテナを使用することができます。
これにより、重要なデータを安全に保管し、必要に応じて復元することが可能になります。
busyboxとtarを用いたmysql-volumeのバックアップ方法
すでに作成したmysql-volumeを試しにバックアップしてみましょう。
データの整合性を保つ観点のため、
できれば、バックアップするボリュームを使用しているコンテナを停止しておきましょう。
これは docker stopでできます。
次に、下記のようなコマンドを実行します。
docker run --rm -v mysql-volume:/src -v $(pwd):/backup busybox tar cvf /backup/backup.tar -C /src .-v mysql-volume:/srcは、ボリュームマウントの指定です。
mysql-volume(バックアップしたい Docker ボリュームの名前)をコンテナ内の /src ディレクトリにマウントします。
これにより、コンテナ内からボリュームのデータにアクセスできるようになります。
-v $(pwd):/backupは、これもボリュームマウントの指定ですが、
こちらはホストシステムの現在のディレクトリ($(pwd) )を、
コンテナ内の /backup ディレクトリにマウントします。バックアップデータはここに保存されます。
busyboxは、多くの標準的な UNIX ユーティリティを含む軽量のイメージで、
ここでは tar コマンドの実行に使用されます。tarを実行したいだけなので、
ぶっちゃけ、busyboxじゃなくても、ubuntuでもcentosでも
tarが叩ければ何でもいいです。
tar cvf /backup/backup.tar -C /src . は、コンテナ内で実行されるコマンドです。
tar コマンドを使って /src(mysql-volume がマウントされたディレクトリ)の内容を、
/backup/backup.tar にアーカイブします。
-C /src オプションは tar に /src ディレクトリに移動してからアーカイブを作成するよう指示し、
. は現在のディレクトリ(ここでは /src)の全てのファイルとディレクトリを意味します。
結果として、このコマンドは mysql-volume の内容をバックアップして、ホ
ストシステムの現在のディレクトリに backup.tar という名前のアーカイブファイルとして保存します。
バックアップが完了した後、使用したコンテナは自動的に削除されます。
ただ、これはLinuxとかならうまくいくはずですが、
docker desktop for macのような仮想化を使った環境だと、
カレントディレクトリにファイルが作られない模様。
先程のvolumeの中身にnsenterを使ったような、
別のアプローチが必要になるかもしれません。
ただ、そもそもdocker desktop for macとかなら、
アプリの拡張機能とかで、GUIでバックアップ作成できるっぽいので、
そもそもコマンドでやる必要ないのかもしれません。
https://www.docker.com/ja-jp/blog/back-up-and-share-docker-volumes-with-this-extension/
私は、docker desktop for macではなく、
OrbStackというものを使っているので、
もう少しコマンドでなんとかできないものか調査してみようと思います。
ボリュームの復元(リストア)方法
ボリュームのデータを復元するには、
基本的に新しいvolumeを作成して、
先程のバックアップとパスが逆向きのtarコマンドを実行すれば復元できるはずです。
新しいvolumeを作成するには、
docker volume create new-volume-nameとします。
次にバックアップファイルの配置です。
復元するバックアップファイル(例えばtarアーカイブ)が、
ホストシステム上のアクセス可能な場所にあることを確認します。
(docker desktop for macとかだとそもそもここがうまく行っていないので、
あくまでlinuxとかの話になります)
そしたら、バックアップデータを新しく作成したボリュームに抽出します。
一時的なコンテナを作成し、バックアップファイルをマウントして、新しいボリュームにデータを抽出するコマンドを実行します
docker run --rm -v new-volume-name:/target -v /path/to/backup:/backup busybox tar xvf /backup/backup.tar -C /target新しいボリュームにデータが正しく復元されたことを確認します。
必要に応じて新しいボリュームを使用するコンテナを起動し、データを確認します。
また復元の手段としては、volumes-fromなどもあります。




