
本記事では、
SQLにおけるデータ型とWhere句、
条件式、様々な演算子について解説します。
SQLのdockerにおける環境構築、
4大命令の簡単な解説については、
前回のこちらの記事や動画を御覧ください。
データ型
SQLにおけるデータ型は、データベース内の各列(カラム)に格納されるデータの種類を定義します。
このデータ型によって、例えば数値を管理するデータに
文字列などが混入することを防いで、データの安全性を保つことに寄与しています。
データ型には、数値、文字列、日付などがあります。
プログラミング言語の経験がある人は、
データ型と言われたら、ピンと来るかと思います。
基本的には、それらと似たような感じです。
ただ、SQLは、他のプログラミング言語に比べても、
割とデータ型が細かい印象があります。
TypeScriptとかに慣れていると、
データ型の多さに圧倒されるかもしれません。
それに比べて、
各DBMS製品によっても、
微妙にデータ型が違ったりするので、
正直全部をご紹介するのは無理です笑
それに、実際によく使うデータ型は、
割とパターンが決まっているので、
それらを押さえれば、意外と十分だったりします。
どういうデータ型があるのか、
一覧で知りたいという場合は、
その都度、そのDBMS製品のドキュメントを確認する形で
問題ないと思います。
本記事ではMySQLのデータ型を取り上げます。
細かいところは、他のDBMS製品と違ったりするかもしれませんが、
大枠は同じかと思います。
https://dev.mysql.com/doc/refman/8.0/ja/data-types.html
数値データ型
数値データの場合、大きく分けて、
整数型と小数点型があります。
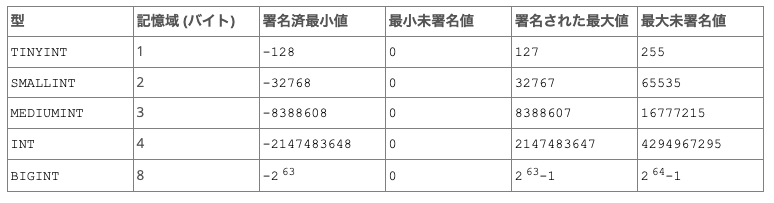
整数型だと、
ポイント
INT:標準の整数型。
SMALLINT:より小さな範囲の整数。
TINYINT:非常に小さな整数。
MEDIUMINT:中程度の範囲の整数。
BIGINT:非常に大きな範囲の整数。
などがあります。
これらの型は、符号付き(負の値を含む)または符号なし(正の値のみ)で使用できます。
これに対して、浮動小数点型だと、
ポイント
FLOAT:単精度浮動小数点数。
DOUBLE:倍精度浮動小数点数。
などがあり、固定小数点型だと
ポイント
DECIMAL:固定小数点数
などがあります。
固定小数点と浮動小数点の大まかな違いとしては、
その精度にあります。
金融データなど、固定の小数点精度が必要な場合は DECIMAL 型を使用します。
一方で、科学計算などのより広い範囲の数値で精度がそれほど重要でない場合は FLOAT または DOUBLEなど
が良かったりします。
ただ、実際のところ、
この中でもよく使うのは、
INTやBIGINTが圧倒的に多く、
それ以外のデータ型も使わないわけではありませんが、
上記2つに比べると、遭遇シーンは下がると思うので、
基礎というレベルでは、そこまで全てを覚える必要性はあまりないかもしれません。
文字列データ型
次に文字列データ型について紹介します。
有名どころとしては、
ポイント
CHAR (固定長の文字列。CHAR(5)は、5文字の文字列を格納します。)
VARCHAR (可変長の文字列。VARCHAR(255)は、最大255文字の文字列を格納できます。)
TEXT型 (長い文字列用。TINYTEXT、MEDIUMTEXT、LONGTEXT:さまざまなサイズの非常に長い文字列用。)
などがあります。
一応これ以外にも、BLOB型とかBINARY型とかありますが、
基礎のレベルじゃなくなるので割愛します。
上記の3つの型については、
遭遇シーンが多いと思うので、
まずはこれらをおさえるだけでも十分だと思います。
さて、固定長と可変長というキーワードがありますが、
これらの違いは何かというと、
データ型の領域を中身のサイズに合わせて調整するか、
しないかという感じです。
はい、これじゃ意味わからないですよね。
具体例として、
CHAR(10)とVARCHAR(10)があるとします。
これはそれぞれ、10文字までのデータ型を格納することができます。
違いは、例えば「test」などのように、
10文字に満たない文字を格納した場合です。
固定長のCHARの場合は、
あらかじめ10文字文の領域を確保しているため、
「test」というデータが来たら、
10文字に満たない部分は、空白が追加されます。
すなわち、「test 」みたいなデータが入るイメージです。
これに対して、可変長のVARCHARの場合は、
データである「test」というサイズに合わせて、
データを格納するので、
「test」と空白は追加されず、そのままの長さで格納します。
これが固定長と可変長の違いです。
まあでも、一般的には、
ここまで厳密な違いを考慮しているかというと微妙で、
小さい文字列データ型なら、CHAR、
普通ぐらいなら、VARCHAR、
長いテキストデータなら、TEXTという感じで、
分けていることが多い気がします。
日時データ型
次に日時データ型です。
主なものとしては、
ポイント
DATE:日付のみを格納(例: 2024-01-15)。
TIME:時間のみを格納。
DATETIME:日付と時刻を格納。
TIMESTAMP:UNIXタイムスタンプを格納。
YEAR:年を格納。
などという感じです。
正直、日時データ型だけで、
こんなにいろいろ種類があるのは、
あまりない気がします。
これだけ色々あると、
もはや基礎と呼べるか怪しいですが、
日時データ型自体はよく出てくるので、
軽くご紹介しました。
ここに関しては、
突き詰めると細かすぎるので、
詳細は、下記のドキュメントに譲ります。
https://dev.mysql.com/doc/refman/8.0/ja/date-and-time-types.html
データ型の選択について
適切なデータ型を選択することは、ストレージの効率、パフォーマンスの最適化、
およびデータの正確性を保証するために重要です。
例えば、不必要に大きなデータ型を選択すると、
ストレージ領域の無駄遣いやパフォーマンスの低下を引き起こす可能性があります。
一方で、データに合わない小さなデータ型を選択すると、データの切り捨てや精度の損失が発生する恐れがあります。
したがって、データの特性を理解し、それに応じて最も適切なデータ型を選択することが不可欠です。
ストレージ効率として、 適切なデータ型を選択することで、データベースのストレージ使用量を最適化できます。
例えば、小さな整数を格納するために INT を使用するよりも TINYINT を使用する方が効率的です。
先述しましたが、小数とかの場合は必要な精度を考慮することが重要で、
金融データなど正確な小数点以下の値が必要な場合、DECIMAL型の使用が良いのかと思います。
Where句
Where句は、SQLクエリで特定の条件に一致する行を選択するために使用されます。
Whereを指定しないと、すべての行が対象になるので、
DELETEやUPDATEとかでは、ほぼ必須みたいなものになるかと思います。
データベースから特定のデータを抽出する際にWhere句は不可欠で、
条件に一致するデータのみを取得することで、効率的なデータ管理が可能になります。
4大命令において、INSERTの場合は、
新規追加になるため、「どの行」を指定する必要がないので、
Where句は使用することができません。
肝心のWhereの使い方としては、
後ろに条件式を記述し、絞り込みを行います。
条件式
条件式は、主にWhere句内で使用され、特定の条件を指定するために用いられる式です。
文法は、Where 条件式という感じです。
条件式は、結果が真か偽になるものなので、
他のプログラミング言語における、booleanと思っていただければ、
問題ないかと思います。
たとえば、hiredate > '2023-01-01'なら、問題ない一方、
hiredate + '2023-01-01'みたいなものは記述できません。
他のプログラミング言語だと、
後者の場合でもboolean変換できますが、
SQLの場合、あくまで「どの行」を指定するための、
Where句なので、こういう変化球は使えないという感じですかね。
SELECT * FROM employees WHERE hiredate > '2023-01-01';このクエリは、2023年1月1日以降に雇用された従業員のデータを選択します。
演算子
上記のクエリーで出てきた、
Where句内の、>のように、
条件式で使う演算子には様々なものがあります。
比較演算子
まず>のような演算子は、
比較演算子といい、
下記のようなものがあります。
ポイント
= (等しい)
< (左辺は右辺より小さい)
> (左辺は右辺より大きい)
<= (左辺は右辺の値以下)
>= (左辺は右辺の値以上)
<> または != (左右の値が等しくない)
上5つは直感的だと思いますが、
<>や!=は見慣れないかもしれません。
これらは等しくないことを表します。
また、NULLのデータに対して、
=などの比較演算子では判断できないというのもあり、
NULLのデータを探したいときは、
IS NULLやIS NOT NULL演算子を使います
さて、これらの=などの比較演算子以外のものとしては、
下記のようなものがあります。
ポイント
LIKE (パターンマッチング、部分一致)
BETWEEN (範囲指定)
IN
LIKE演算子
LIKE演算子の場合、
パターン文字というものを使うことができます。
これは、プログラミング言語でいう、
正規表現とかワイルドカードみたいなイメージです。
%と_の2つがあり、
%は、任意の0文字以上の文字列を表し、
_は任意の一文字を表します。
SELECT * FROM employees WHERE name LIKE '%yamada%';このクエリでは、パターン文字として、%を使っているので、
yamadaの前後に0文字以上の文字列があるものをSelectするという感じになります。
すなわち、名前に「yamada」という文字が含まれる従業員を選択します。
ちなみに、yamada100%みたいな、
%自体が含まれる行を抽出したい場合は、
そのまま、LIKE '%yamada100%'みたいにすると、
最後の%がパターン文字として認識されてしまうので、
エスケープという作業をして上げる必要があります。
SELECT * FROM employees WHERE name LIKE '%yamada100$%' ESCAPE '$';ここで出てきたESCAPE句というもので、指定した$という文字のあとは、
ただの文字として扱うことができるので、
上記のクエリーで元気100%の行を抽出することができます。
BETWEEN演算子
次にBETWEEN演算子についてです。
BETWEEN演算子は、間という意味の通り、
範囲指定したい際に使用します。
文法的には、
BETWEEN 値1 AND 値2という感じで記述し、
値1以上かつ値2以下のとき、真となります。
SELECT * FROM employees WHERE hiredate BETWEEN '2023-01-01' AND '2023-12-31';このクエリは、2023年1月1日から2023年12月31日までの間に雇用された従業員を選択します。
IN / NOT IN演算子
IN演算子は、指定されたリスト内にあるいずれかの値に一致する行を選択するために使用されます。
これは、複数の候補値の中から一致するものを見つける際に非常に便利です。
SELECT * FROM employees WHERE ID IN (3, 5, 7);このクエリは、ID が3、5、7のいずれかである従業員を選択します。
これに対して、NOT INは逆で、
指定されたリストに含まれないすべての行を選択するために使用されます。
これは、特定の値を除外したい場合に有用です。
SELECT * FROM employees WHERE ID NOT IN (3, 5, 7);このクエリは、ID が3、5、7以外の従業員を選択します。
論理演算子
Where句の条件式において、
複数の条件式を書きたい場合、
ANDやORのような論理演算子を使用することで
実現することができます。
ANDは2つの条件式の両方が真のとき、真になり、
ORは2つの条件式のどちらかが真なら、真となります。
SELECT * FROM employees WHERE hiredate >= '2023-01-01' AND name LIKE '%yamada%';このクエリは、2023年1月1日以降に雇用され、名前に「山田」を含む従業員を選択します。
また、NOT演算子というものもあり、
これを使うと、真偽値を反転させることができます。
SELECT * FROM employees WHERE NOT (salary > 50000);このクエリは、給与が50,000より大きくない(つまり50,000以下の)従業員を選択します。
集合演算子
SQLの集合演算子は、複数のクエリ結果セットを組み合わせたり、比較したりする際に使用されます。
主な集合演算子にはUNION、EXCEPT(またはMINUS)、INTERSECTがあります。
UNIONの場合、
SELECT employee_id FROM sales_department
UNION
SELECT employee_id FROM marketing_department;のように使うことができます。
UNION演算子は、二つのクエリ結果セットの全ての行を結合します。重複する行は一つにまとめられます。
平たく言うと、和集合になります。
このクエリは、販売部門とマーケティング部門の両方から従業員IDを取得し、重複する従業員IDは排除して結果を表示します。
ただ、結合するクエリのカラム数とデータ型が一致していないと行けないので、
正直集合演算子を使う場面は限定的になるかと思います。
上記のサンプルコードのように、
2つのテーブル構造がある程度似ていて、
抽出する際は、揃える必要があるので、
例えば、ほぼ同じデータ構造のテーブルが複数ある際の、
総合的な分析とかで使うのが一番使うシーンなのかなと思います。
このUNIONに対して、
EXCEPTは差集合、INTERSECTは積集合という位置づけになります。
集合の種類が変わるだけで、
文法的にはほぼ同様です。
差集合の場合、最初のクエリの結果セットから、
二番目のクエリの結果セットに含まれる行を除外します
積集合は、和集合と同じく、
SELECT文の順番はあまり関係なく、
共通行を取得してくれます。
case演算子
SQLのCASE演算子は、条件に基づいて異なる値を返すために使用されます。
これは、条件分岐の機能をクエリに組み込む際に非常に便利です。
まあ他のプログラミング言語における、
CASEと似ているといえば似てますかね。
CASE文は、特定の条件に基づいて異なる結果を返す際に使用され、
WHEN-THEN句を使用して、特定の条件を指定し、それに対応する結果を定義します。
ELSE句を使用して、どのWHEN条件にも一致しない場合のデフォルト値を指定できます。
CASE文はSELECT、UPDATE、ORDER BYなどのさまざまな場所で使用できます。
SELECT id, name
CASE
WHEN salary > 50000 THEN 'High salary'
WHEN salary > 30000 THEN 'Medium salary'
ELSE 'Low salary'
END as SalaryCategory
FROM employees;このクエリは、employeesテーブルの従業員ごとに給与カテゴリを判断し、それに応じたラベルを付けて表示します。
UPDATEとかでの使用例としては、
UPDATE employees
SET bonus = CASE
WHEN performance = 'Excellent' THEN 1000
WHEN performance = 'Good' THEN 500
ELSE 0
END;このクエリは、employeesテーブルの従業員のパフォーマンスに基づいてボーナス額を更新します。
余談ですが、CASE演算子は、
実際のところ、たまに使用する程度ですが、
面接の技術テストとかで聞かれやすいトピックな気がしています。
私はCASE演算子について即答できなかったので、
落とされるということを何度か経験しました(苦笑い)
初期構築用SQLファイル
本記事と同じような状態で、
試す場合は、下記のsqlファイルを使うと
スムーズかと思います。
CREATE DATABASE testdb;
use testdb;
create table employees (id INT AUTO_INCREMENT PRIMARY KEY, name varchar(25), salary int, bonus int, department varchar(25), performance char(25), hiredate date);
insert into employees (name, hiredate, salary, bonus, department, performance) values ('yamada', '2023-09-12', '60000', '30', 'sales', 'Good');
insert into employees (name, hiredate, salary, bonus, department, performance) values ('satou', '2023-04-12', '30000', '100', 'sales', 'Good');
insert into employees (name, hiredate, salary, bonus, department, performance) values ('yamada100%', '2024-09-12', '60000', '30', 'HR', 'Excellent');このファイルを作成したら、
コンテナ立ち上げ時に、
docker cpをします。
docker cp test.sql mysql-sample:/これで、mysql-sampleコンテナの
ルートパスにファイルがコピーされました。
あとは、docker exec -it mysql-sample /bin/bashで
コンテナに入って、
mysql -u root -p < test.sqlでファイルを実行することができます。




