
本記事では、SQLにおける、
テーブル結合と、CREATE TABLEなどをはじめとした、
DDLについて解説します。
また、それらに関連して、
NOT NULLをはじめとしたDBレベルので制約と、
主キーと外部キーについても言及します。
本記事は、前回の記事などに比べると、
やや高度なトピックになるかもしれませんが、
DBを実務レベルで運用することを踏まえると、
絶対におさえておきたい知識なので、
ぜひとも最後までご覧ください。
DDL
さて、前々回ぐらいの記事で、
初期構築についてのSQLをちらっと紹介しました。

ここで出てきた、CREATE TABLE などのように、
データベースの構造を定義、変更、削除するための言語をDDL(データ定義言語)と総称します。
他には、ALTER、DROPなどがあります。
ちなみに、SELECTなどの4大命令は、
DML(データ操作言語)の中に該当します。
DMLに比べると、DDLを使う頻度は、
少し下がるかもしれませんが、
ORMとかを使わない開発の場合、
嫌でも使わないと何もできないので、
ぜひともおさえておきたい知識だと思います。
CREATE TABLE
早速、DDLの中で、
おそらく最も著名なCREATE TABLEについて紹介します。
これは、すでに前々回ぐらいの記事でも
初期構築スクリプトの中で出てきているので、
馴染み深いかもしれません。
その名のとおり、CREATE TABLE文は新しいテーブルをデータベースに作成するために使用されます。
テーブル名とそれが持つべき列(カラム)とそのデータ型、さらには各種制約(NOT NULLなど)を指定することができます。
制約はテーブルに格納されるデータの正確性、一貫性、信頼性を保証するためのものと思っていただければ。
(制約の種類については後述します)
CREATE DATABASE testdb;
use testdb;
CREATE TABLE Departments (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL
);
insert into Departments (name) values ('HR');
insert into Departments (name) values ('sales');
CREATE TABLE Employees (
id INT AUTO_INCREMENT PRIMARY KEY,
firstname VARCHAR(100) NOT NULL,
lastname VARCHAR(100) NOT NULL,
email VARCHAR(255) UNIQUE,
position VARCHAR(100),
salary DECIMAL NOT NULL,
bonus INT,
performance CHAR(25),
hiredate DATE DEFAULT '2024-01-01',
department_id INT,
FOREIGN KEY (department_id) REFERENCES Departments(id)
);
insert into Employees (firstname, lastname, hiredate, salary, bonus, performance, department_id) values ('tarou', 'yamada', '2023-09-12', '60000', '30', 'Good', 1);
insert into Employees (firstname, lastname, hiredate, salary, bonus, performance, department_id) values ('hanako', 'satou', '2023-04-12', '30000', '100', 'Good', 1);
insert into Employees (firstname, lastname, hiredate, salary, bonus, performance, department_id) values ('syouta', 'yamada100%', '2024-09-12', '60000', '30', 'Excellent', 2);
これは、Employeesというテーブルを作成し、
カラムとして、id firstname, position, salary, hiredateなどが存在するという感じですね。
デフォルト値
上記のクエリーで、hireDate DATE DEFAULT '2024-01-01' という部分があったと思います。
ここのDEFAULTというものは、
デフォルト値を指定する構文で、列にデフォルト値を指定すると、
その列に値が指定されなかった場合に自動的に設定される値を定義できます。
insert into Employees (firstname, lastname, salary) values ('mike', 'satou', 300.0);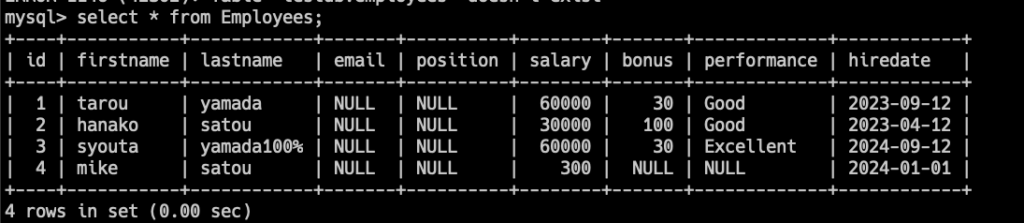
一番下の行の、hiredateを見ると、
デフォルト値として設定した、2024-01-01が入っていることが確認できます。
これは、特定のデータが欠けている場合のデフォルト設定や、
特定の値が頻繁に使用される場合に便利です。
デフォルト値を指定しないと、
NULLが混入しやすくなりますが、
データとしてNULLが混入することを防ぎたいときに指定すると効果的かと思います。
NULLとは?
そもそも、NULLって何だっけっていう話ですが、
NULLは、フィールド(列)の値が存在しない、または不明であることを示します。
これは、データベース内の特定のフィールドに値が割り当てられていない場合に使用されます。
NULLは「0」や空文字列とは異なり、「何もない」や「値不明」のようなニュアンスのものです。
NULL値を持つデータを扱う際には注意が必要で、SQLでは、NULLは特殊な扱いを受け、
通常の値とは異なるルールが適用されます。
たとえば、どんな値とNULLを比較しても結果はNULLになります
(例: NULL = NULL の結果はNULL)。
これは、NULLが「不明」を意味するため、不明な値同士が等しいかどうかを判断することはできないからです。
そのためこうしたNULLが混入するのを防ぐために、
デフォルト値や後述する、NOT NULL制約など活きてくるという感じになります。
NOT NULL制約
firstname VARCHAR(100) NOT NULL, にあるような、
NOT NULL制約は、列にNULL値を許容しないことを指定します。
仮に、firstnameを指定せずにinsertするとエラーが出ます。

すでに言及しましたが、NULLが紛れ込むと何かと面倒なことが多く、
特に値が入ることが想定されているカラムには、
この制約をつけることが一般的です。
まあ基本的に、このカラムはNULLが入っても大丈夫かなという、
カラム以外は指定しておいた方が無難な制約かと思います。
(必要に応じてDEFAULT値も指定して)
CHECK制約
CHECK制約は、列に格納される値が指定した条件を満たす必要があることを指定します。
NOT NULL制約とかに比べると、少しマイナーかもしれません。
これにより、特定の範囲の値のみを列に許容するなど、データの正確性をさらに強化できます。
Railsとかのフレームワークだと、バリデーションでよくねってなるかもしれませんが、
DBレベルでのCHECK制約をつけるのも、アプリケーションによっては、
重要になってくるかもしれないので、ぜひとも覚えておきたい制約です。
UNIQUE制約
UNIQUE制約は、テーブルの特定の列または列の組み合わせに対して、
それぞれの行で値が一意(重複しない)であることを保証するために使用されます。

Duplicate entry という感じでエラーになっていますね。
データベース内で一意の識別子やキーを確保する際に重要ですが、
主キー(PRIMARY KEY)制約とは異なり、NULL値の重複を許容します
DROP TABLE
DROP TABLE文は、データベースから指定されたテーブルを削除するために使用されます。
この操作は一度実行されると、テーブルに含まれるすべてのデータ、テーブル定義、
およびテーブルに関連する制約やインデックスなどが完全に削除されます。
従って、DROP TABLE文を使用する際には、削除するテーブルに重要なデータが含まれていないか、
またはデータが適切にバックアップされているかを慎重に確認することが重要です。
基本的な文法としては、
DROP TABLE テーブル名;テーブル名は削除したいテーブルの名前です。
DROP TABLE Employees;この場合、Employeesテーブルを削除します。
ALTER TABLE
ALTER TABLE文は、既存のテーブルの構造を変更するために使用されます。
テーブルに新しい列を追加したり、既存の列を削除または変更したり、
制約を追加または削除したりすることができます。
ALTER TABLEはデータベースの柔軟性を高め、
アプリケーションの進化に合わせてデータモデルを適応させることができる非常に強力なツールです。
DDLの中では、何かと使用頻度が高い文法にあたるかなと思います。
ALTER TABLE Employees
ADD SecondEmail VARCHAR(255);このコマンドは、EmployeesテーブルにSecondEmailという名前の新しい列を追加します。
列のデータ型はVARCHAR(255)です。
ALTER TABLE Employees
DROP COLUMN SecondEmail;このコマンドは、EmployeesテーブルからSecondEmail列を削除します。
ALTER TABLE Employees modify Salary DECIMAL(15,2);この例では、EmployeesテーブルのSalary列のデータ型をDECIMAL(15, 2)に変更します。
これにより、より大きな数値をSalary列に格納できるようになります。
※ちなみに、DECIMAL(15, 2)とは、15は全体の桁数(精度)で、
2は小数点以下の桁数(スケール)を指します。
つまり、この定義では最大で15桁の数字を扱うことができ、そのうち2桁が小数部分に割り当てられるという感じです。
ちなみに、ただDECIMALとした場合は、DECIMAL(10, 0)と同じ意味になります。
https://dev.mysql.com/doc/refman/8.0/ja/fixed-point-types.html
テーブルの結合
さて、お次はテーブルの結合について言及していきます。
テーブル結合は、複数のテーブルからデータを結合して一つの結果を生成する強力な機能です。
テーブル結合を適切に使用することで、データベースからのデータ取得をより柔軟に、効率的に行えるようになります。
主キーと外部キー
テーブル結合に際して、
重要な概念として主キーと外部キーというものがあり、
テーブル内の各レコードを一意に識別するための列を主キーと呼び、
他のテーブルの主キーを参照するための列を外部キーと呼びます。
主キーに設定されたフィールドは、NULLを含むことができず、
データの整合性を保つために、テーブル内でその値は一意でなければなりません。
Departments テーブルにおける id 列が主キーにあたります。
一方で外部キーは、
Employees テーブルにおける department_id 列があたります。
テーブルの結合条件として、主キーと外部キーを使用し、
下記で紹介するINNER JOINやOUTER JOINなどを行います。
内部結合(INNER JOIN)
早速、結合の種類ですが、
大きく分けて、内部結合と外部結合があり、
結合すべき相手の行が見つからないとき、
行が消滅するものを内部結合(INNER JOIN)といいます。
INNER JOINは、二つのテーブル間で共通するデータのみを結合して取得します。
この結合タイプは、一般的に使用される結合方法の一つです。
SELECT Employees.firstname, Departments.name
FROM Employees
INNER JOIN Departments ON Employees.department_id = Departments.id;このクエリは、EmployeesテーブルとDepartmentsテーブルをdepartment_idとidで結合し、
従業員の名前とそれに対応する部署名を取得します。

外部結合(OUTER JOIN)
内部結合であれば、
行が消滅してしまうようなものを、
出力するのを外部結合と総称し、
下記のような種類があります。
LEFT JOIN (LEFT OUTER JOIN)
LEFT JOIN (またはLEFT OUTER JOIN) は、左テーブルの全てのレコードと、
それと一致する右テーブルのレコードを取得します。
一致するレコードが右テーブルに存在しない場合、右テーブルのフィールドはNULLとして返されます。
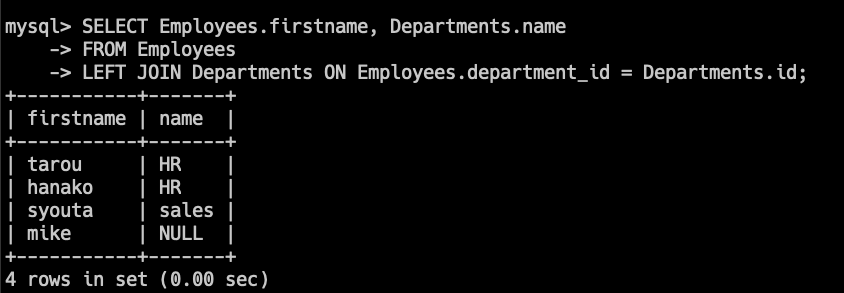
SELECT Employees.firstname, Departments.name
FROM Employees
LEFT JOIN Departments ON Employees.department_id = Departments.id;このクエリでは、すべての従業員と、該当する場合はその部署名を取得します。
部署に所属していない従業員も結果に含まれ、そのdepartment.nameはNULLとなります。
RIGHT JOIN (RIGHT OUTER JOIN)
RIGHT JOIN (またはRIGHT OUTER JOIN) は、左テーブルと右テーブルを結合しますが、
結果セットには右テーブルの全レコードが含まれ、左テーブルの一致するレコードのみが表示されます。
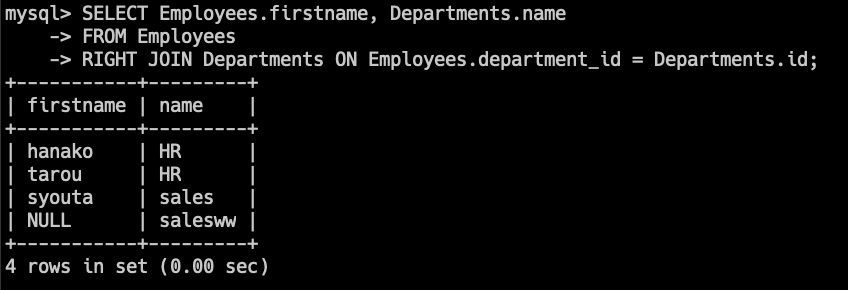
SELECT Employees.firstname, Departments.name
FROM Employees
RIGHT JOIN Departments ON Employees.department_id = Departments.id;このクエリでは、すべての部署と、該当する場合はその部署に所属する従業員の名前を取得します。
従業員がいない部署も結果に含まれ、そのnameはNULLとなります。
CROSS JOIN
CROSS JOINは、一つのテーブルの各レコードを他のテーブルの
全レコードと組み合わせた結果を生成します。
この結合は、特定の一致条件を指定しないため、結果セットは通常非常に大きくなります。
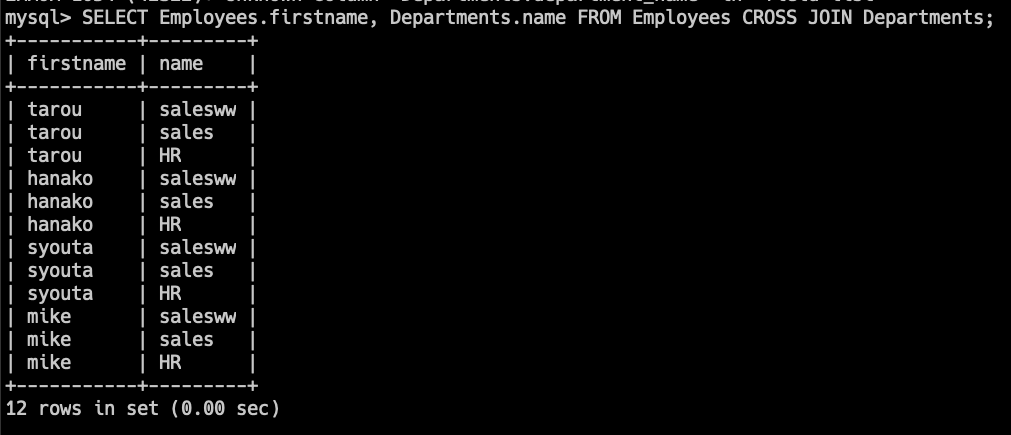
SELECT Employees.firstname, Departments.name
FROM Employees
CROSS JOIN Departments;このクエリでは、Employeesテーブルのすべての従業員と、Departmentsテーブルのすべての部署の組み合わせを取得します。
正直、inner joinやouter joinに比べて、
圧倒的に使用頻度が下がるので、
正直、知らなくてもあんまり問題ない気もしますが、
ピンポイントにクエリー分析で組み合わせとかを算出したいときなどは、
知っておくと便利かもしれません。




