
本記事では、SQLにおける、
グループ化について解説します。
データを集約し、特定の条件でフィルタリングする際に、
Group ByとHaving句というものを使用して、
グループ化をすることができます。
グループ化は、めちゃくちゃ使うというわけでもないのですが、
知っておくべき必須教養みたいな側面はあるので、
ぜひとも押さえておきたい知識です。
また、グループ化は、
基本的に集計関数といっしょに使うことが多いので、
集計関数をはじめとした様々な関数について詳しく知りたい方は、
こちらの記事も併せて御覧ください

SQLのグループ化
早速本題に入りたいのですが、
環境構築については、
下記の記事で紹介しているので、
こちらでDockerのMySQLコンテナが立ち上がっていると想定します。
-

-
参考【Docker DBコンテナ構築】データベースの種類やSQLの概要解説
データベース(DB)とは? あまりに身近すぎて、今更感がすごいですが、改めてデータベースとは何でしょうか? データベースは、様々なデータを整理して格納するためのシステムですね。割とそのまんまですね 非 ...
続きを見る
今回はグループ化なので、
部署テーブルなどを作っおく必要があるので、
初期構築のスクリプトについては、
下記の記事を御覧ください。
-

-
参考【SQLデータ型】Where句と条件式における演算子
本記事では、SQLにおけるデータ型とWhere句、条件式、様々な演算子について解説します。 SQLのdockerにおける環境構築、4大命令の簡単な解説については、前回のこちらの記事や動画を御覧ください ...
続きを見る
GROUP BY
まず、Group Byについてです。
SQLの集計に際し、検索結果をグループごとのまとまりに分ける機能があり、
それが、Group Byにあたります。
例えば、単にSUM(salary) とかとすると、
すべての合計が算出されますが、
これを例えば、Departmentの営業部だけの合計を算出したいなどというときに、
Group Byは使えます。
Group By句は、SQLにおけるデータ集約の基本て、
特定の列を基にして、データをグループ化し、
それぞれのグループに対して集計関数(例:SUM、AVG、COUNT)を適用したいときに
使用するでしょう。文法としては、下記のような感じで、
GROUP BYで指定する列とSELECTの最初の列が同様という感じです。
SELECT 列1, 集計関数(列2)
FROM テーブル
(WHERE 絞り込み条件)
GROUP BY 列1;例えば、下記のようなテーブルがあったとします。
| ID | Department | salary |
| 1 | sales | 6000 |
| 2 | sales | 3000 |
| 3 | HR | 3000 |

このテーブルに対して、
Departmentごとの平均給与を計算するSQLは以下の通りです。
SELECT department, AVG(Salary) AS AverageSalary
FROM Employees
GROUP BY department;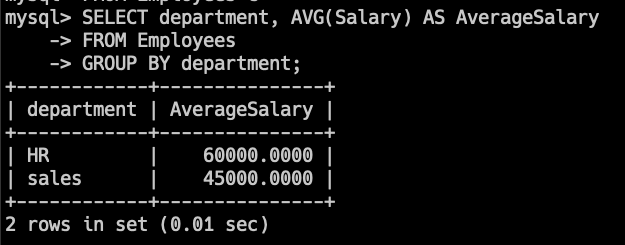
この場合、salesが60000 + 30000 / 2 = 45000になり、
HRはそのまま60000になっているので、
確かに部署ごとの平均給与になっていますね。
最初のうちは、混乱するかもしれませんが、
要するに複数のレコードにおいて、
同じ値が出ることが想定されるカラム(上記でいうと部署のように)に対して、
全データにおいて、その値においてグループ化したいというときに使用できるのが、
Group byという感じです(余計わかりにくくなった...?)
グループ化の流れとして、
例えば、Where句などもある場合は、
先にWhereによる絞り込みが行われてから、
その表に対して、グループ集計が行われます。
そのため、集計し終わったものに対しての絞り込みは、
Whereが最初に絞り込みを行う関係上、
Whereでは行うことはできません。
そこで使用するのが、次に紹介する、
Having Byとなります。
HAVING句
Having句は、Group Byによってグループ化されたデータに対するフィルタリングを行います。
Where句と似ていますが、Having句は集約関数と共に使用される点が異なります。
SELECT 列1, 集計関数(列2)
FROM テーブル
GROUP BY 列1
HAVING 集計関数(列2) 条件;HAVING句にも、
Whereと同様に条件式を書くので、
使い方としては、ほぼ同様です。
異なるのは、その実行タイミングという感じです。
平均給与が46000以上の部門だけを表示するSQLは以下の通りです。
SELECT Department, AVG(Salary) AS AverageSalary
FROM Employees
GROUP BY Department
HAVING AVG(Salary) > 46000;
上記のクエリーでHavingの部分を省略すると、
sales | 45000の結果も取得されるので、
確かにHaving句で結果を絞っていることがわかると思います。
ちなみに、このHavingとGroup byを踏まえて、
最終的なSELECT文をまとめると、
SELECT文は下記のような文法となります。
select 列1
from テーブル名
(where 条件式)
(group by グループ化列)
(having 集計結果に対する条件式)
(order by 並び替えたい列)Group ByとHaving句の組み合わせ
Group ByとHaving句を組み合わせることで、より複雑なデータ集約とフィルタリングが可能になります。
例えば、各部門で最高給与を得ている従業員の数をカウントするには以下のようにします。
SELECT Department, MAX(Salary) AS MaxSalary, COUNT(ID) AS NumberOfEmployees
FROM Employees
GROUP BY Department
HAVING COUNT(ID) > 1;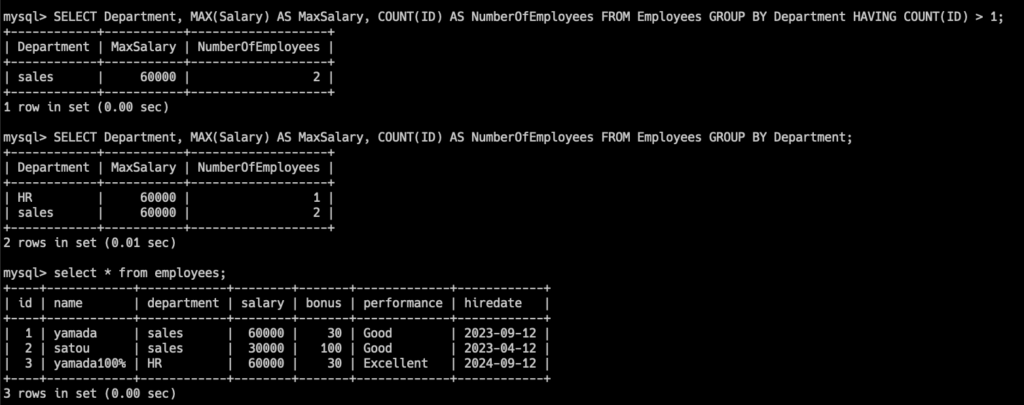
一番上のクエリーの場合、HAVING COUNT(ID) > 1 と条件を加えているため、
一人しかいないHRのデータは取得できていません。
2つ目のクエリのように、
HAVING句をなくすと、
部署ごとの最高給与とそのレコード数を出すので、
HRの方は1、salesは2と出していますね。
WITH ROLLUP 修飾子
MySQLにおいては、
グループ化について、
WITH ROLLUPというものが使えます。
https://dev.mysql.com/doc/refman/8.0/ja/group-by-modifiers.html
WITH ROLLUPは、MySQLでGROUP BY句と共に使用されるオプションで、
集約されたデータに加えて、合計値を計算するために使用されます。
階層的な集約結果を簡単に取得でき、データの概要を把握しやすくなります。
WITH ROLLUPを使用すると、GROUP BYで指定された列の各組み合わせに対する集約結果に加えて、
それらの組み合わせの全体の合計を得ることができます。
SELECT Department, sum(Salary) AS AverageSalary FROM Employees group by department with rollup;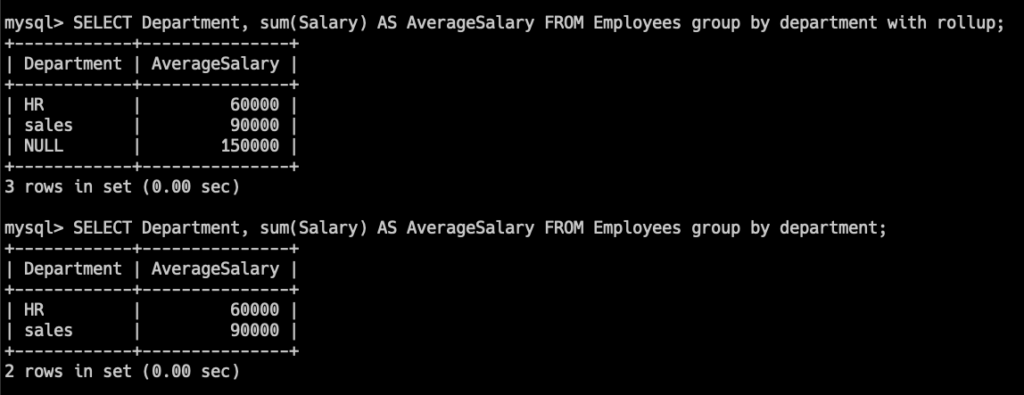
画像のように、with rollupを付け加えることで、
AverageSalaryの合計値を出すことができますね。




