
本記事では、検索結果の加工として使われる、
DISTINCT、ORDER BYなどを始め、
LENGTHやCOALESCEなどの様々な関数について
紹介します。
前回の記事はこちらです。
ハンズオンで試したい方は、前回の記事と前々回の記事で
DockerのSQLの環境構築を紹介しているので、
そちらを御覧ください。
また、Youtube動画の方もあるので、
文字より動画の方が良いという方は、
こちらもご参考ください。

SELECTにおける検索結果の加工
早速、検索した結果を加工するための文法として、
DISTINCT、ORDER BY、OFFSET-FETCHについて
取り上げます。
特に、前2つはよく使うので、
覚えておくと便利かと思います。
DISTINCT
SQLのDISTINCTは、クエリ結果から重複する行を除外し、
ユニークな行のみを取得するために使用されます。
データベース内の重複を排除し、
特定のカラムに存在する異なる値のセットを取得する際に特に便利です。
SELECT DISTINCT文を使用して、重複を除去します。
一つ以上のカラムを指定することができ、指定されたカラムの組み合わせがユニークな行のみが選択されます。
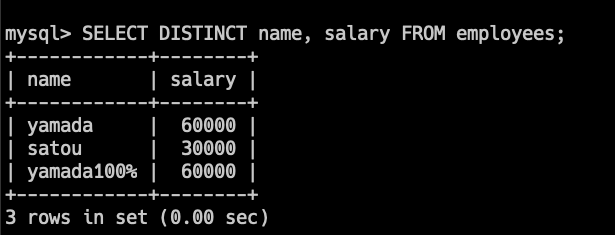
SELECT DISTINCT salary FROM employees;上記のクエリは、employeesテーブルのsalaryカラムから
重複する給料を除外したユニークなリストを取得します。
SELECT DISTINCT name, salary FROM employees;こっちのクエリでは、employeesテーブルからsalaryとnameの組み合わせで
ユニークな行のみを取得します。
そのため、先程のsalaryだけだと、
重複するものも、nameとの組み合わせで重複していない場合は、
取得できます。
ORDER BY
次に、SQLのORDER BYです。
こちらは、クエリ結果を特定のカラムまたは複数のカラムに基づいて並べ替えるために使用されます。
これにより、データを特定の順序(昇順や降順)で表示することが可能になります。
ORDER BY句は、SELECT文の最後に配置し、
デフォルトでは昇順(1, 2, 3...)(ASC)で並び替えられますが、
降順(3, 2, 1...)(DESC)で並び替えることもできます。
複数のカラムに基づいて並び替えることも可能です。
SELECT * FROM employees ORDER BY salary;このクエリは、employeesテーブルのレコードを給与(salary)の昇順で並び替えて表示します。
つまり、一番給与が低い人が先頭に表示されます。
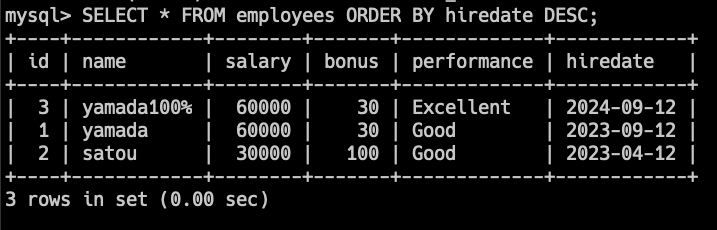
SELECT * FROM employees ORDER BY hiredate DESC;こちらのクエリでは、employeesテーブルのレコードを雇用日(hiredate)の降順で並び替えます。
つまり、一番最近に入社した人が先頭に表示されますね。
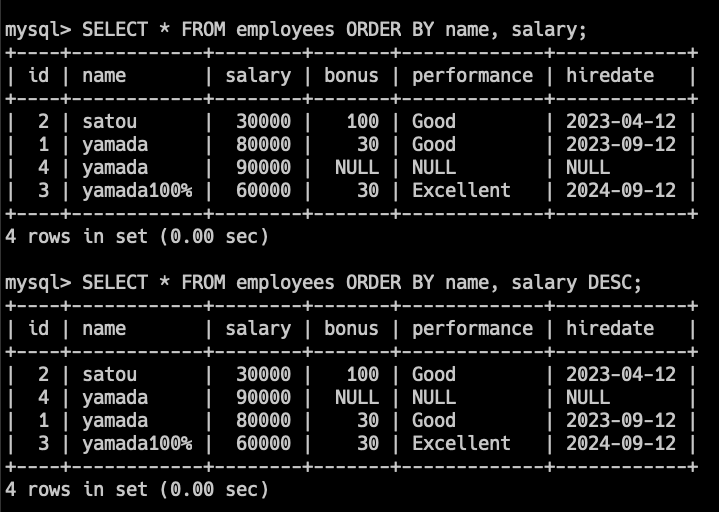
SELECT * FROM employees ORDER BY name, salary DESC;上記のクエリでは、employeesテーブルのレコードをまずnameの昇順(デフォルト)で並び替え、
次に給与(salary)の降順で並び替えて表示します。
複数の列で並べ替える際は、最初に指定した列で並べ替えてから、
同じ値がある際に次の列の値で並べ替えられます。
ORDER BYを使わないSelectにおいても、
なんとなく昇順で並び替えられたものが出力されていたかもしれませんが、
ORDER BYを使わないSELECTにおけるデータの並び順は、
保証されず、実質ランダムです。
そのため、必ずこの並び順にしてほしいという場面では、
ORDER BYは必須になるでしょう
OFFSET - FETCH
お次は、OFFSETです。
少しマイナーですね。
それに加えて、DBMS製品によっては、
使えないこともあるので、
上2つに比べると、重要度は下がるかと思います。
OFFSET-FETCH句は、SQLクエリの結果から特定の範囲の行だけを取得するために使用されます。
これは、大量のデータがある場合にページネーション(データの分割表示)などを行う際に特に便利です。
OFFSET句は、スキップする行数を指定します。
FETCH句は、取得する行数を指定します。
OFFSET - FETCH句単体でも、多くのDBMS製品で使用できますが、
この句は通常、ORDER BY句と組み合わせて使用されます。
SELECT * FROM employees ORDER BY name OFFSET 2 ROWS FETCH NEXT 1 ROWS ONLY;こんな感じのクエリーです。
ただ、このクエリーはmysqlではサポートされていないので、
mysqlでは、LIMITという別のものを使用する必要があります。
SELECT * FROM employees ORDER BY name LIMIT 1 OFFSET 2;もしかすると、こちらの方がメジャーかもしれませんね。
関数
さてお次は、SQLにおける、
関数について紹介します。
関数自体はプログラミング言語でおなじみの概念ですし、
SQLにおいても基本的な概念は変わりません。
本記事では、こうした関数の中で
良く使われるものをいくつか紹介します。
そもそも、関数とは何かというと、
与えられたもの(引数)を、特定の処理を行うことで、
別の値(戻り値)に変換してくれるものを良います。
関数自体の詳細な解説は、
こちらの記事のほうがわかりやすいかもしれません。
-

-
参考【TypeScript関数】アロー関数やコールバック関数とオプショナル引数
関数とは何か? TypeScriptに限らず、プログラミング言語のほとんどには、関数という概念があります。 変数が、値を使いまわしたり、名付けをしたりすることができる箱であるなら、関数は、処理を使いま ...
続きを見る
MySQLにおける組み込みの関数は、
かなりの種類があって、
すべてを紹介するのは難しいので、
著名で良く使いそうなものをご紹介します。
より細かい関数については、
下記のドキュメントを御覧ください
https://dev.mysql.com/doc/refman/8.0/ja/built-in-function-reference.html
LENGTH
まず最初がLENGTHです。
LENGTH関数は、文字列の長さをバイト数で返す関数です。
この関数は、データベース内で文字列データの処理において役に立ちます。
基本的なLENGTH関数の構文は以下の通りです。LENGTH(文字列)
テーブルに保存する文字列のバイトサイズを確認し、特定のサイズを超えるデータの取り扱いを決定する際に使用したり、
特定のフィールドに保存されるデータの長さを制限する必要がある場合、LENGTH関数を用いてデータ長をチェックしたりします。
SELECT LENGTH('hello');このクエリは、'hello'という文字列のバイトサイズを返します。
注意点としては、文字数ではなく、
バイト数を返すので、マルチバイト文字(漢字とか平仮名など)が含まれている場合は、
複数のバイトとしてカウントします。
'hello'のような英語の場合は、
通常バイト数は、文字数と思ってもらっても問題ないかと思います。
SUBSTRING
SUBSTRING関数は、文字列関数の一つであり、
文字列の特定の部分を抽出するために使用されます。
この関数は、データのフォーマットや
データの部分的な表示において役に立ちます。
基本的なSUBSTRING関数の構文は以下の通りです。SUBSTRING(文字列, 開始位置, [長さ])
長い文字列から特定の部分だけを表示する必要がある場合、SUBSTRING関数を使用してその部分を抽出できるので、
ログファイルや大量のテキストデータから特定の情報を抽出する際にも使用されます。
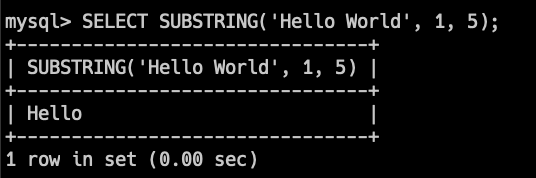
SELECT SUBSTRING('Hello World', 1, 5);このクエリは、'Hello World'の最初の5文字、つまり'Hello'を返します。
SELECT SUBSTRING('MySQL Database', 6);このクエリは、6番目の文字から始まる文字列、つまり'Database'を返します。
CONCAT
CONCAT関数は、複数の文字列を結合するために使用されます。
この関数は、データの表示やデータベース内の情報の組み合わせにおいて有用です
CONCAT関数は、二つ以上の文字列を結合して一つの文字列を作成し、
基本的なCONCAT関数の構文は以下の通りです。CONCAT(文字列1, 文字列2, …, 文字列N)
データのフォーマット変更やレポートの作成などで
使えそうですね。
データベース内の情報を組み合わせて、動的にクエリを生成する際にも使用されます。
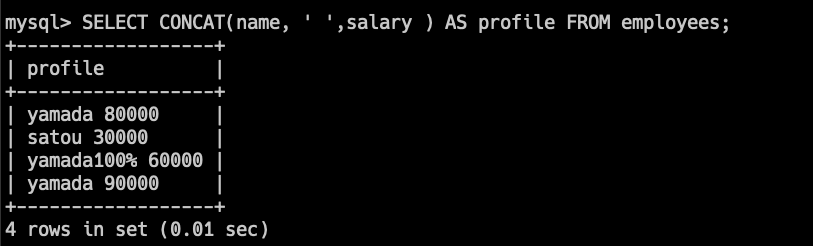
SELECT CONCAT('Hello', ' ', 'World');このクエリは、'Hello'と'World'を結合して'Hello World'を返します。
SELECT CONCAT(name, ' ',salary ) AS profile FROM employees;このクエリは、従業員テーブルの名前と給与の列を結合して、
簡単なprofileを表示します。
ROUND/TRUNC
お次は、小数の丸め処理系です。
ROUND関数とTRUNC関数は、数値の丸め処理を行うために使用される関数です。
これらの関数は、データの整形や計算において重要な役割を果たします。
ROUND関数は、指定された小数点以下の桁数に基づいて数値を丸めます。
基本的なROUND関数の構文は以下の通りです。ROUND(数値, 小数点以下の桁数)
一方で、TRUNC関数(またはTRUNCATE関数)は、指定された小数点以下の桁数で数値を切り捨てます。
基本的なTRUNC関数の構文は以下の通りです。TRUNCATE(数値, 小数点以下の桁数)
会計や財務報告において、数値を特定の小数点以下の桁数で丸めるときに、
ROUND関数は使用されることが多いです。
データ分析やレポート作成などで、数値データをより整った形で表示したいときは、
TRUNC関数を使用することが多いかと思います。
SELECT ROUND(123.4567, 2);このクエリは123.4567を小数点以下2桁で丸め、123.46を返します。
SELECT TRUNCATE(123.4567, 2);このクエリは123.4567を小数点以下2桁で切り捨て、123.45を返します。
POWER
POWER関数も、数学関数の一つで、
ある数値を指定されたべき乗に上げるために使用されます。
使い方としては、第一引数を第二引数で指定されたべき乗に上げます。
基本的なPOWER関数の構文は以下の通りです。POWER(基数, べき指数)
複雑な計算処理やデータ分析において、
べき乗の計算を行う際に使用されるかと思います。
SELECT POWER(2, 3);このクエリは、2の3乗、つまり8を返します。
CURRENT_DATE/CURRENT_TIME/CURRENT_TIMESTAMP
お次は日付系の関数です。
CURRENT_DATE, CURRENT_TIME, CURRENT_TIMESTAMPは、
現在の日付や時刻を取得するために使用される関数です。
これらの関数は、データのタイムスタンプ記録、スケジューリング、
レポート作成において役に立つかと思います。
CURRENT_DATE関数は、現在の日付をYYYY-MM-DDの形式で返します。
データの日付単位でのフィルタリング、レポーティング、および日付に基づく計算に使用されます。
CURRENT_TIME関数は、現在の時刻をHH:MM:SSの形式で返します。
時刻に基づいてデータを処理する場合や、レポートでの時間記録などに使用するかと思います。
CURRENT_TIMESTAMP関数は、現在の日時をYYYY-MM-DD HH:MM:SSの形式で返します。
データのタイムスタンプ記録、日時に基づくトリガーやイベントのスケジューリングなどに使用されます。
SELECT CURRENT_DATE();このクエリは現在の日付を返します。
SELECT CURRENT_TIME();このクエリは現在の時刻を返します。
SELECT CURRENT_TIMESTAMP();このクエリは現在の日時を返します。
CAST
CAST関数は、あるデータ型を別のデータ型に変換するために使用される関数です。
データベースでのデータ操作において非常に重要な役割を果たします。
この関数を使用することで、文字列を数値に、数値を日付に、等々、
さまざまな形式のデータ型変換が可能になります。
基本的なCAST関数の構文は以下の通りです。CAST(変換したい値 AS 変換後のデータ型)
用途としては、データ型の不一致を解消したり、
特定のフォーマットでデータを表示したい場合に使用されます。
異なるデータ型を持つ列を比較する際や、結合する際に、データ型の不一致が問題になることがあるので、
CAST関数を使用してデータ型を揃えることで、これらの問題を解決できます。
それ以外だと、 文字列型の数値を数値型に変換してから計算を行う必要がある場合など、
CAST関数が有効です。
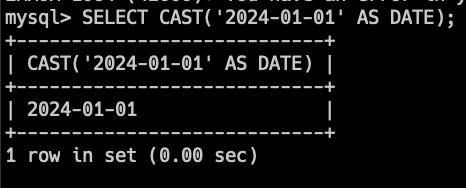
SELECT CAST('2024-01-01' AS DATE);このクエリは文字列 '2024-01-01' を日付型に変換します。
COALESCE
COALESCE関数は、SQLで使用される関数の一つで、
引数リストの中から最初の非NULL値を返します。
この関数はNULL値を扱う際の便利なツールです。
すべての引数がNULLの場合、結果もNULLとなります。
これは、ややマイナーな気もしますが、
知っておくと結構便利な関数かと思います。
基本的なCOALESCE関数の構文は以下の通りです。COALESCE(値1, 値2, …, 値N)
主にNULL値を扱う際に使用され、NULL値をデフォルト値や代替値に置き換えるのに役立ちます。
テーブルの列にNULL値が含まれている場合、COALESCE関数を使用して特定のデフォルト値を設定できます。
計算や集計を行う際にNULL値を特定の数値に置き換える必要がある場合に便利です。
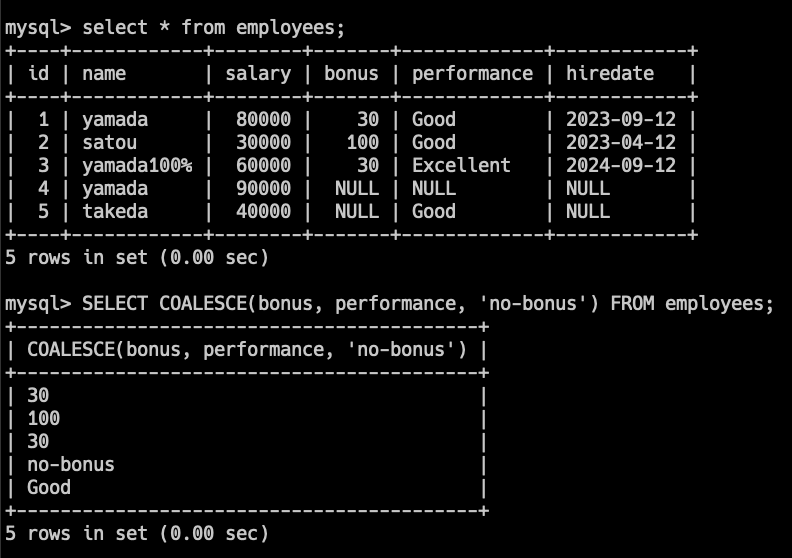
SELECT COALESCE(NULL, NULL, 3, NULL, 5);このクエリは3を返します(最初の非NULL値)
SELECT COALESCE(bonus, performance, 'no-bonus') FROM employees; bonus列がNULLの場合、performance列の値が使用されます。両列ともNULLの場合、'no-bonus'が表示されます。
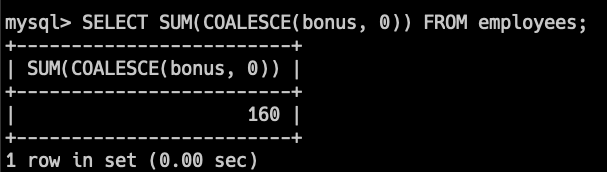
SELECT SUM(COALESCE(bonus, 0)) FROM employees; このクエリでは、bonus列がNULLの場合、0が使用され、bonusの合計が計算されます。
SUM/MAX/MIN/AVG
お次は、集約関数系統です。
SUM, MAX, MIN, AVGといった集約関数は、
データ分析やレポート作成において広く使用されます。
SUM関数は、指定された列の数値の合計を計算します。
合計売上、合計コスト、総ポイント数など、数値データの合計が必要な場合に使用されます。
MAX関数は、指定された列の最大値を返します。
最高売上、最大温度、最高スコアなど、データセット内の最大値を見つける場合に使用されます。
MIN関数は、指定された列の最小値を返します。
最低売上、最小温度、最低スコアなど、データセット内の最小値を見つける場合に使用されます。
AVG関数は、指定された列の平均値を計算します。
平均売上、平均温度、平均評価など、数値データの平均が必要な場合に使用されます。
SELECT SUM(bonus) FROM employees;このクエリは、employeesテーブルのbonusの合計を計算します。
SELECT MAX(bonus) FROM employees;このクエリは、bonusの最高額を返します。
SELECT MIN(bonus) FROM employees;このクエリは、bonusの最低額を返します。
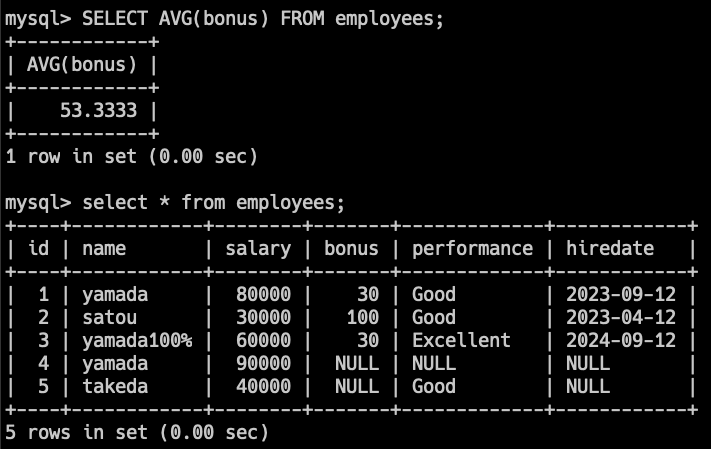
SELECT AVG(bonus) FROM employees;このクエリは、bonusの平均を計算します。
nullの値がある場合は、それを無視して計算するので、
160 / 3 = 53.33333333を返します。
nullにデフォルト値を入れたい場合は、
先述した、COALESCEを使うのが良いでしょう。
COUNT
COUNT関数も、集約関数の一つであり、
テーブル内の行数または特定の条件に一致する行数をカウントするために使用されます。
基本的なCOUNT関数の構文は以下の通りです。COUNT(列名または*)
SELECT COUNT(*) FROM employees;このクエリはemployeesテーブルの全行数をカウントします。
SELECT COUNT(*) FROM テーブル名 WHERE 条件;特定の条件に一致する行数をカウントしたい場合は、
上記のようなクエリーにします。




